
البحث لم يعد يبحث عن كلمات، بل يبحث عن معنى
هناك تحول جوهري يحدث الآن في أنظمة البحث لا يلتفت إليه معظم المتخصصين في تحسين محركات البحث. Google لم يعد يعالج استعلامات المستخدمين كسلاسل نصية يبحث عن تطابقها في صفحات الويب. بل أصبح يعالجها كإشارات دلالية مرتبطة بالرسم البياني المعرفي (Knowledge Graph)، ويفسرها من خلال الكيانات والعلاقات والسياق.
هذا يعني أن جودة فهم محرك البحث لمحتواك لم تعد تتحدد بعدد الكلمات المفتاحية التي تستخدمها، بل بمدى وضوح الكيانات التي يحتويها المحتوى، ومدى دقة تصنيفها، ومدى ثبات هذه الإشارات الكيانية عبر الزمن.
والسؤال الذي يطرح نفسه بقوة: ما الأداة الأفضل لاستخراج هذه الكيانات وتحليلها؟ هل يمكننا الاعتماد على نماذج الذكاء الاصطناعي التوليدي مثل ChatGPT وDeepSeek وGemini؟ أم أن واجهات البرمجة المتخصصة مثل Google Cloud NLP وAmazon Comprehend لا تزال ضرورية؟
لمعرفة الإجابة، أجرينا دراسة معيارية محاكاة شاملة قارنت سبعة أنظمة عبر 15 نصاً إخبارياً معقداً، وثلاثة تشغيلات لكل نموذج على كل نص، وقياس أبعاد متعددة تشمل الدقة والاسترجاع والاتساق والبيانات الوصفية والانجراف الدلالي. والنتائج كانت كاشفة.
المشكلة التي لا ينتبه لها أحد
معظم فرق تحسين محركات البحث اليوم تستخدم أحد نهجين لاستخراج الكيانات من المحتوى. الأول يعتمد على واجهات برمجة متخصصة في معالجة اللغة الطبيعية (NLP APIs) مثل Google Cloud NLP التي صُممت تحديداً لمهمة استخراج الكيانات وتصنيفها. الثاني يعتمد على نماذج لغوية توليدية كبيرة (LLMs) مثل ChatGPT يُطلب منها استخراج الكيانات من خلال تعليمات نصية (prompts).
المشكلة الحقيقية هي أن معظم الناس يخلطون بين قدرتين مختلفتين تماماً:
الفهم الدلالي (Semantic Understanding): القدرة على فهم المعنى والسياق والعلاقات الضمنية. هنا تتفوق النماذج التوليدية.
الاستخراج المنظم (Structured Extraction): القدرة على تحويل النص إلى بيانات منظمة قابلة للتكرار والقياس مع بيانات وصفية كمية. هنا تتفوق واجهات البرمجة المتخصصة.
أن يفهم النموذج أن “الكرملين” في سياق إخباري يعني “الحكومة الروسية” وليس مبنى في موسكو، هذا فهم دلالي. لكن أن يستخرج هذا الكيان بنفس الطريقة في كل مرة يُشغَّل فيها على نفس النص، ويعطيه درجة ثقة رقمية ودرجة بروز ورابطاً لقاعدة المعرفة، هذا استخراج منظم. والفرق بين الاثنين هو الفرق بين أداة بحث يمكن الوثوق بها وأداة تعطيك نتائج مختلفة في كل مرة.
كيف صممنا التجربة المعيارية
صممنا مجموعة اختبار مكونة من 15 نصاً إخبارياً محاكاة تغطي موضوعات بالغة التعقيد: السياسة النقدية الأمريكية وقرارات الفيدرالي، والنزاع الروسي الأوكراني والعقوبات، وتنظيم الذكاء الاصطناعي في الاتحاد الأوروبي، وأسواق النفط وديناميكيات أوبك+، وأرباح إنفيديا وصناعة أشباه الموصلات، والانتخابات الرئاسية الأمريكية، والعلاقات الصينية التايوانية، وسياسة البنك المركزي الأوروبي، وتنظيم العملات المشفرة، والاندماجات والاستحواذات، وقمة المناخ COP28، والانتخابات الهندية، وأزمة بوينغ، والتمويل المغامر، والطوارئ الصحية العالمية.
لماذا اخترنا نصوصاً إخبارية؟
استُلهمت بنية النصوص من أنماط الكتابة والكثافة الكيانية والتعقيد الجيوسياسي الموجود في المصادر الصحفية الدولية الكبرى مثل Reuters وBloomberg وFinancial Times وAP News وThe Economist وCNBC وThe Wall Street Journal. لم يُستخدم أي محتوى محمي بحقوق نشر. المجموعة الاختبارية مُركبة بالكامل لكنها تحاكي الأنماط الفعلية للصحافة المالية والسياسية من حيث كثافة الكيانات والغموض الدلالي وتعقيد المشاعر.
اخترنا هذا النوع من النصوص لأنه يضع أنظمة الاستخراج تحت ضغط حقيقي: كنايات جيوسياسية (“الكرملين” و”البيت الأبيض” و”بروكسل”)، ومصطلحات تشريعية (“قانون الذكاء الاصطناعي” و”اختبار هاوي”)، ومؤشرات مالية (S&P 500 وSensex)، ومشاعر متناقضة (أرباح قوية لكن السهم ينخفض).
المنهجية
لكل نموذج من النماذج السبعة، أجرينا ثلاث تشغيلات مستقلة على كل نص. سجلنا المخرجات الخام لكل تشغيل وقارناها مع 235 كياناً مرجعياً حددناها يدوياً مسبقاً. قسنا الدقة (Precision) والاسترجاع (Recall) ومقياس F1 ودقة تصنيف النوع ودقة تحليل المشاعر وثراء البيانات الوصفية ونسبة الاتساق بين التشغيلات ومعدل الانجراف الدلالي.
النتيجة: أكثر من 3,778 صف بيانات خام لاستخراج الكيانات، و315 تحليل مشاعر، و552 خطأ مُوثق عبر ثمانية أنواع.
النتائج التي لم نتوقعها
النتيجة النهائية للمعيار: من يتصدر؟
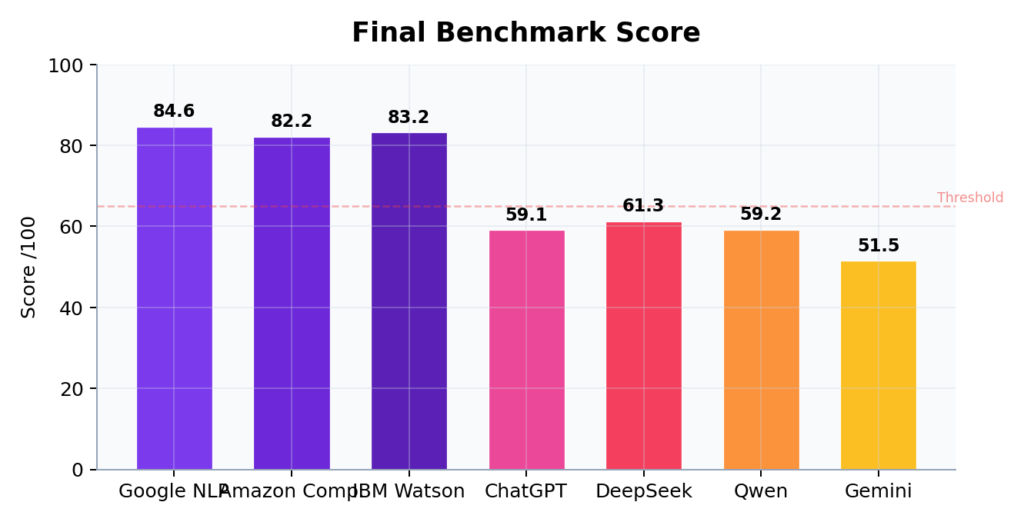
واجهات البرمجة المتخصصة تتصدر بفارق واضح (82-85 نقطة)، بينما النماذج التوليدية تتراوح بين 51 و61 نقطة
على مستوى النتيجة الإجمالية المرجحة، حققت واجهات البرمجة الثلاث درجات تتراوح بين 82 و85 من 100، بينما تراوحت درجات النماذج التوليدية بين 51 و61. لكن هذه الأرقام المجمعة تخفي تفاصيل أكثر أهمية.
DeepSeek يحقق أعلى F1 بين جميع الأنظمة
مقياس F1: التوازن بين الدقة والاسترجاع
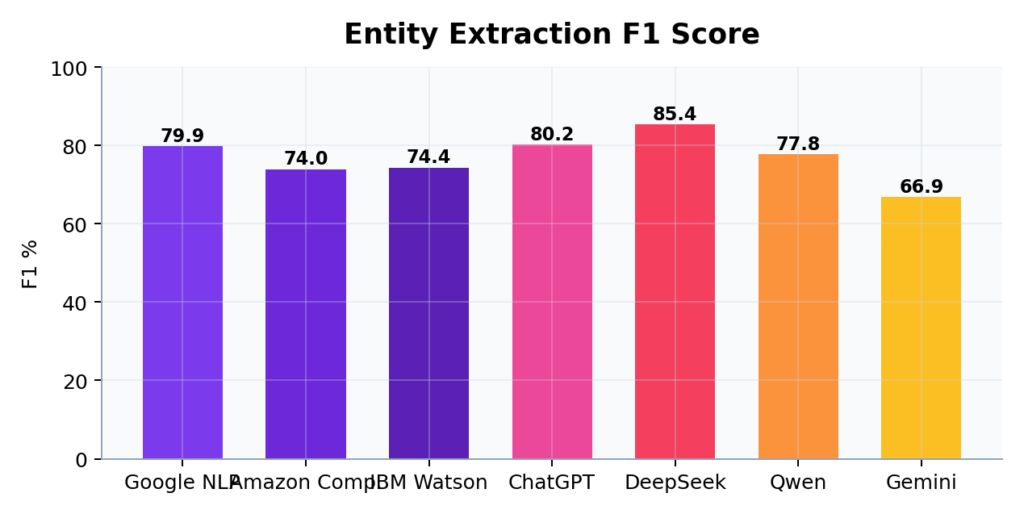
DeepSeek يتصدر بـ85.4% بسبب استرجاعه المرتفع، لكن Google Cloud NLP يقدم أفضل توازن عام
حقق DeepSeek أعلى مقياس F1 بنسبة 85.4% بفضل استرجاعه المرتفع الذي بلغ 80.3%، مما يعني أنه يلتقط أكبر عدد من الكيانات بما فيها المفاهيم الضمنية. لكن هذا الأداء العالي يأتي بثمن سنكتشفه في قسم الاستقرار.
ChatGPT حقق 80.2% مع أقل انجراف بين النماذج التوليدية. Google Cloud NLP حقق 79.9% لكنه يقدم أفضل توازن عام عندما نأخذ البيانات الوصفية والاتساق في الاعتبار. أما Gemini فسجل أضعف أداء بنسبة 66.9%.
الدقة مقابل الاسترجاع: أين يتفوق كل نهج؟
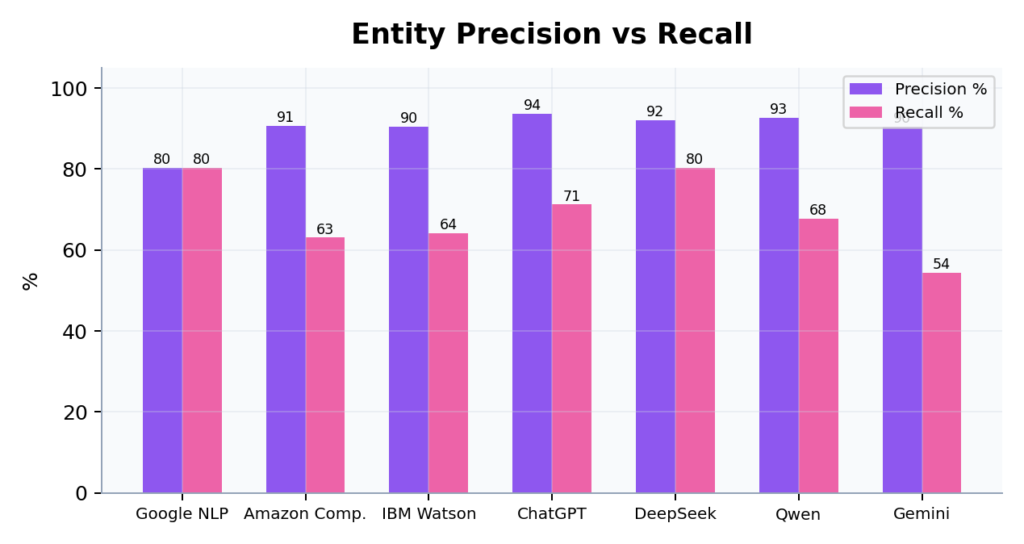
النماذج التوليدية تحقق دقة أعلى ظاهرياً لأنها تستخرج عدداً أقل مع إيجابيات كاذبة أقل
مفاجأة الدقة: لماذا تبدو النماذج التوليدية أدق؟
لاحظنا أن النماذج التوليدية حققت نسب دقة أعلى من بعض واجهات البرمجة. لكن التفسير ليس ما يتبادر إلى الذهن. السبب هو أن واجهات مثل Google Cloud NLP تميل إلى الإفراط في الاستخراج (over-extraction)، حيث تصنف عبارات مفاهيمية عامة ككيانات. هذا يرفع عدد الإيجابيات الكاذبة ويخفض الدقة. لكنه في المقابل يمنحك تغطية أوسع مع بيانات وصفية لكل كيان تمكنك من الفلترة لاحقاً باستخدام عتبة البروز (salience threshold).
لماذا تعتبر البيانات الوصفية نقطة فاصلة؟
ثراء البيانات الوصفية: الفجوة الحاسمة
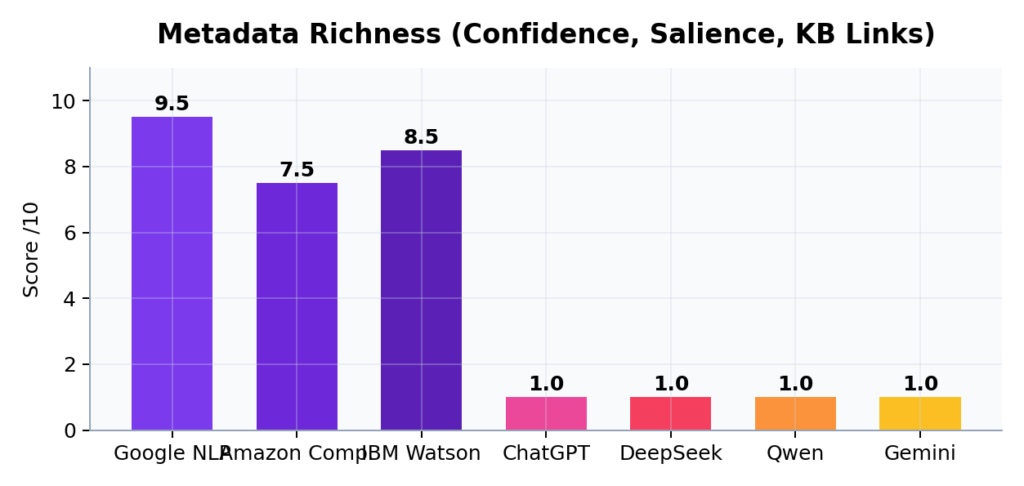
واجهات البرمجة توفر 7.5 إلى 9.5 من 10 في البيانات الوصفية، بينما جميع النماذج التوليدية تحصل على 1.0 فقط
هذه الفجوة هي الأكثر حسماً في الدراسة بأكملها. Google Cloud NLP يوفر لكل كيان مستخرج: درجة ثقة (confidence score) تحدد مدى تأكد النظام من الاستخراج، ودرجة بروز (salience score) تحدد أهمية الكيان في سياق النص الكامل، ورابطاً لقاعدة المعرفة (Knowledge Graph link) يربط الكيان بهويته الرقمية في ويكيبيديا أو Freebase.
في المقابل، عندما تطلب من ChatGPT أو DeepSeek أو Gemini استخراج الكيانات، تحصل على قائمة نصية بدون أي مؤشرات كمية. لا درجة ثقة. لا قيمة بروز. لا رابط معرفي. هذا يعني أنك لا تستطيع:
فلترة الكيانات غير الموثوقة تلقائياً. أو ترتيب الكيانات حسب أهميتها في المحتوى. أو ربط الكيانات بالرسم البياني المعرفي. أو بناء سلسلة عمل آلية قابلة للتوسع. بدون بيانات وصفية، أنت تعمل بدون بوصلة.
مشكلة الانجراف الدلالي: التحدي الأخطر
نسبة تداخل الكيانات بين ثلاث تشغيلات متتالية
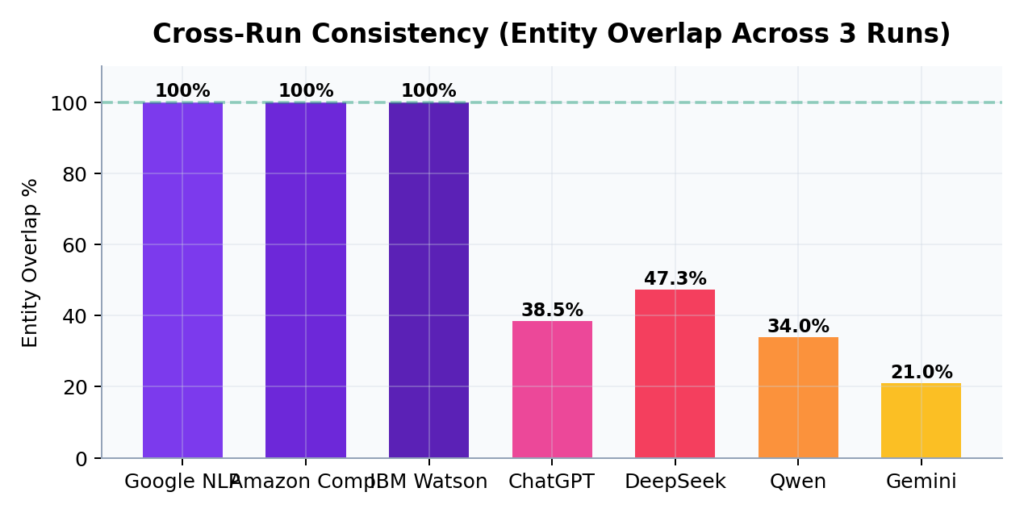
واجهات البرمجة: 100% تطابق. النماذج التوليدية: بين 21% و47% فقط
هذا القسم يكشف الفجوة الأكثر خطورة بين النهجين، والتي نادراً ما يُناقشها أحد.
جميع واجهات البرمجة الثلاث حققت نسبة تطابق 100% عبر ثلاث تشغيلات على كل نص من النصوص الخمسة عشر. هذا يعني أن الكيانات المستخرجة في التشغيل الأول هي نفسها تماماً في التشغيل الثاني والثالث. لا تغيير في الأسماء، لا تغيير في الأنواع، لا تغيير في الدرجات.
في المقابل، سجلت النماذج التوليدية نسب تداخل مروعة:
| النموذج | نسبة التداخل | معدل الانجراف |
| ChatGPT | 38.5% | 61.5% |
| DeepSeek | 47.3% | 52.7% |
| Qwen | 34.0% | 66.0% |
| Gemini | 21.0% | 79.0% |
هذا يعني عملياً: إذا شغّلت ChatGPT على نفس النص ثلاث مرات، فإن 61.5% من مجموعة الكيانات ستختلف بين التشغيلات. تحليل اليوم لن يطابق تحليل الغد. هذا يجعل النماذج التوليدية غير صالحة كمحركات استخراج أساسية في أي سلسلة عمل آلية تتطلب القابلية للتكرار.
ماذا يعني الانجراف الدلالي لأنظمة البحث؟
أنظمة البحث الحديثة تعتمد على إشارات كيانية مستقرة لبناء وصيانة الرسوم البيانية المعرفية. إذا كانت طبقة الاستخراج تنتج إشارات متقلبة، فإن البنية المعرفية بأكملها تصبح غير موثوقة. هذا يؤثر مباشرة على استقرار الترتيب، والظهور في AI Overviews، وأهلية لوحات المعرفة (Knowledge Panels)، والاستشهاد في أنظمة الذكاء الاصطناعي التحادثي.
لكن انتظر: أين تتفوق النماذج التوليدية فعلاً؟
سيكون من غير الأمانة العلمية أن نقول إن واجهات البرمجة أفضل في كل شيء. الحقيقة أن النماذج التوليدية تتفوق في مجالات محددة وجوهرية:
الكيانات المفاهيمية الضمنية
مصطلحات مثل “venture capital winter” و”regulatory overreach” و”agent-mediated information retrieval” و”product-led growth” هي مفاهيم استراتيجية مهمة لا تظهر كأسماء علم في النص. واجهات البرمجة تصنفها عادة كـ”أخرى” (OTHER) أو تتجاهلها بالكامل. النماذج التوليدية تستخرجها وتصنفها ضمن فئات مفاهيمية ذات معنى بنسبة أعلى 15-25% من واجهات البرمجة.
الفهم السياقي العميق
عندما يظهر نص يذكر أن “الكرملين وصف العملية بأنها استفزاز انفصالي”، النموذج التوليدي يفهم أن “الكرملين” هنا يعني الحكومة الروسية وليس مبنى، وأن “استفزاز انفصالي” هو تقييم سياسي وليس وصفاً محايداً. هذا الفهم السياقي قيّم للغاية في مرحلة التفسير.
القدرة على الشرح والتوصية
واجهات البرمجة تعطيك قائمة كيانات. النماذج التوليدية يمكنها شرح العلاقات بين الكيانات، وتحديد الفجوات في التغطية الموضوعية، وتقديم توصيات استراتيجية لتحسين المحتوى. هذه قدرة تفسيرية لا تملكها واجهات البرمجة.
الفكرة الأهم في الدراسة: الاستخراج ليس التفسير
الاستنتاج الأكثر أهمية من هذه الدراسة بسيط لكنه عميق:
واجهات البرمجة المتخصصة والنماذج التوليدية ليست بدائل لبعضها البعض. هي طبقات متكاملة في بنية واحدة. واجهات البرمجة هي طبقة الاستخراج. النماذج التوليدية هي طبقة التفسير. تحتاج إلى الاثنتين معاً.
تصنيف الأخطاء عبر جميع الأنظمة: 552 خطأ مُوثق
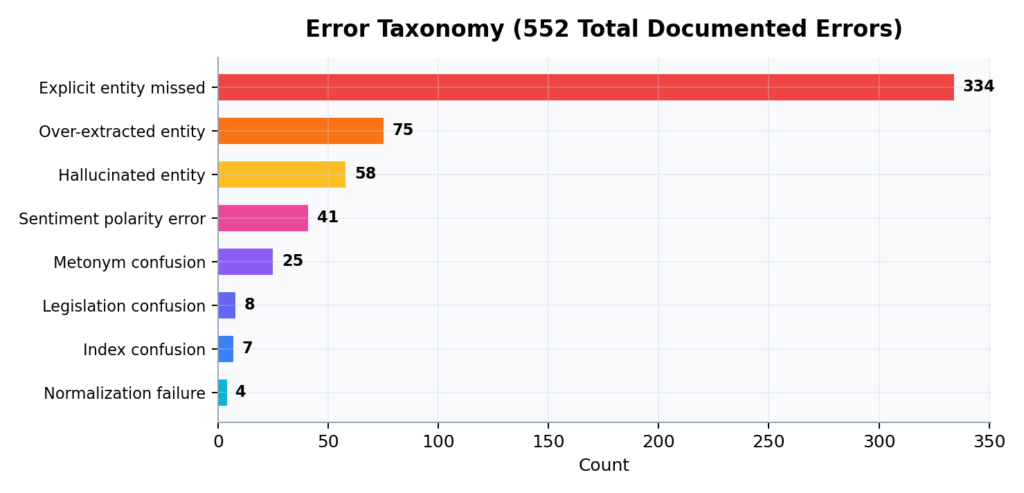
أخطاء الاستخراج (مفقودة + مُختلقة) هي الأكثر شيوعاً، تليها أخطاء التصنيف والمشاعر
طبقة الاستخراج (واجهات البرمجة) تقدم: اتساقاً حتمياً بنسبة 100%، وبيانات وصفية كمية (ثقة، بروز، روابط)، وقابلية التوسع عبر واجهات REST API، والتكامل مع أنظمة الأتمتة. لكنها تعاني من ضعف في استخراج المفاهيم الضمنية وأخطاء تصنيف الكنايات والتشريعات.
طبقة التفسير (النماذج التوليدية) تقدم: فهماً سياقياً عميقاً، واستخراج المفاهيم الضمنية، وشرح العلاقات الكيانية بلغة طبيعية. لكنها تعاني من الانجراف الدلالي وغياب البيانات الوصفية واحتمال الهلوسة.
لماذا المستقبل للبنيات الدلالية الهجينة
الجمع بين النهجين في بنية هجينة متكاملة يُغطي نقاط الضعف المتبادلة ويُنتج نظاماً أقوى من أي مكون بمفرده:
المرحلة الأولى: الاستخراج الحتمي
واجهة برمجة متخصصة (مثل Google Cloud NLP أو Amazon Comprehend) تُجري الاستخراج الأساسي وتُنتج قائمة كيانات مع درجات ثقة وبروز وروابط معرفية. هذه القائمة حتمية وقابلة للتكرار ومناسبة للأتمتة.
المرحلة الثانية: التفسير التوليدي
نموذج لغوي كبير (مثل ChatGPT أو DeepSeek) يتلقى قائمة الكيانات المستخرجة مع النص الأصلي ويُحدد المفاهيم الضمنية المفقودة، ويُحلل العلاقات بين الكيانات، ويُقدم توصيات لتحسين التغطية الموضوعية.
المرحلة الثالثة: محرك القواعد
طبقة قواعد متخصصة تحل مشكلات محددة: تطبيع الكيانات (“Fed” = “Federal Reserve”)، وحل الكنايات (“الكرملين” = “الحكومة الروسية”)، وتصنيف التشريعات والمؤشرات المالية التي تخطئ فيها جميع الأنظمة.
المرحلة الرابعة: المراجعة البشرية
المحلل البشري يتحقق من النتائج ويتخذ القرارات الاستراتيجية النهائية حول أولويات المحتوى وبنية الربط الداخلي وSchema Markup.
ماذا يعني هذا لتحسين محركات البحث والظهور في أنظمة الذكاء الاصطناعي
دقة تحليل المشاعر عبر الأنظمة السبعة
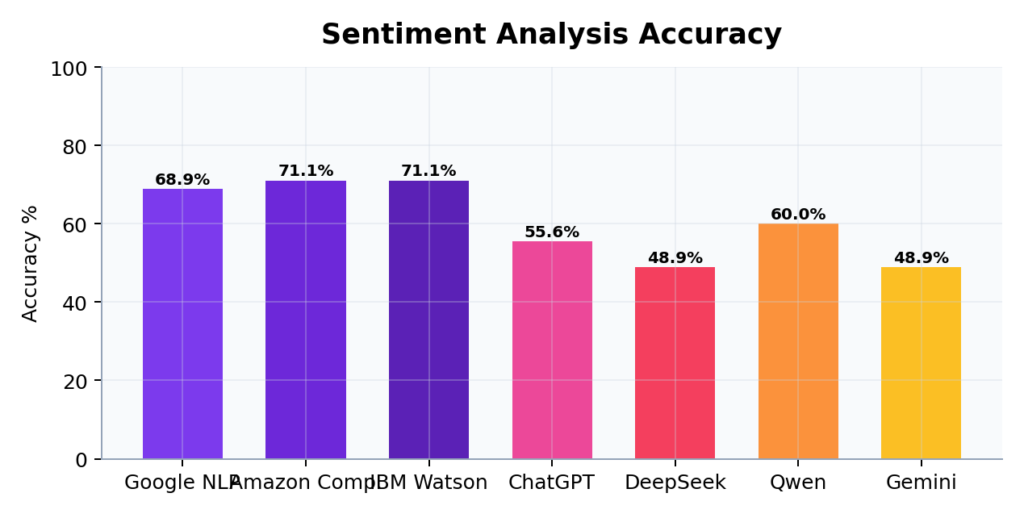
واجهات البرمجة تتراوح بين 69-71%، النماذج التوليدية بين 49-60%. المشاعر المتناقضة تهزم الجميع
أنظمة البحث الحديثة تبني فهمها للمحتوى من خلال الكيانات وعلاقاتها. المحتوى الذي يمتلك ملفاً كيانياً غنياً (كيانات منظمة مع درجات بروز وروابط معرفية، بالإضافة إلى تغطية مفاهيمية شاملة) يتمتع بفرص أعلى للظهور في:
نتائج البحث التقليدية. والملخصات المولدة بالذكاء الاصطناعي (AI Overviews). ولوحات المعرفة (Knowledge Panels). وأنظمة الاستشهاد في أدوات الذكاء الاصطناعي التحادثي مثل ChatGPT وPerplexity.
الاتساق شرط أساسي للسلطة الموضوعية
بناء السلطة الموضوعية (Topical Authority) يتطلب إشارات كيانية مستقرة عبر الزمن. إذا كان نظام الاستخراج ينتج نتائج مختلفة في كل تشغيل، فإن إشارات السلطة الموضوعية المبنية عليه تصبح متقلبة وغير موثوقة. لهذا السبب، الاتساق ليس ميزة إضافية بل متطلب أساسي في أي بنية SEO قائمة على الكيانات.
خط الأنابيب الذي يحدد كيف يفهم محرك البحث محتواك
محرك البحث يعالج محتواك عبر مسار: تفسير الكيانات، ثم تمييز الكيان المحدد (Disambiguation)، ثم ربطه بالكيانات المرتبطة (Association)، ثم تقييم الأهمية والسلطة (Scoring)، وأخيراً تحديد الترتيب (Ranking). استخراج الكيانات هو نقطة البداية. إذا فشل، تتدهور كل مرحلة لاحقة.
الخاتمة: المستقبل ليس لأي نهج بمفرده
مستقبل أنظمة البحث الدلالي القابلة للتوسع لا يكمن في واجهات البرمجة المتخصصة وحدها ولا في النماذج اللغوية الكبيرة وحدها. يكمن في بنيات دلالية هجينة تجمع بين:
أنظمة استخراج حتمية توفر الاتساق والبيانات الوصفية والبنية المنظمة. وأنظمة تفسير توليدية توفر الفهم السياقي والتغطية المفاهيمية. وأنابيب بيانات وصفية منظمة تربط الكيانات بالرسوم البيانية المعرفية. ومنطق حل الكنايات والتطبيع لمعالجة الحالات التي تهزم كلا النهجين.
هذا النهج الهجين ليس مجرد حل تقني. هو متطلب استراتيجي لأي مؤسسة تسعى إلى بناء حضور قوي في أنظمة البحث المدعومة بالذكاء الاصطناعي. المؤسسات التي تتقن هذه البنية ستحظى بحضور غير متناسب في لوحات المعرفة والملخصات التوليدية وأنظمة الاستشهاد. أما التي تعتمد على نهج أحادي فستواجه فجوات تفسيرية متزايدة مع تطور أنظمة البحث.
النماذج اللغوية الكبيرة أنظمة تفسير ممتازة. لكنها أنظمة استخراج غير موثوقة. المستقبل ليس في الاستبدال، بل في الدمج الذكي.
هذه الدراسة جزء من سلسلة أبحاث SEODataDriven حول البنيات الدلالية المتقدمة والظهور في أنظمة الذكاء الاصطناعي. للاطلاع على مجموعة البيانات المعيارية الكاملة أو مناقشة كيفية تصميم بنية هجينة لمؤسستك:
[email protected] | seodatadriven.com

